Project Overview
TRAR (Personalized Trip Recommendation with Attractive Routes) is a machine learning system that generates personalized travel itineraries by considering both the attractiveness of destinations (Points-of-Interest) and the routes connecting them. Unlike traditional recommendation systems that focus solely on POI popularity, TRAR evaluates route quality using metrics like the Gini coefficient and gravity models to create more engaging and satisfying travel experiences.
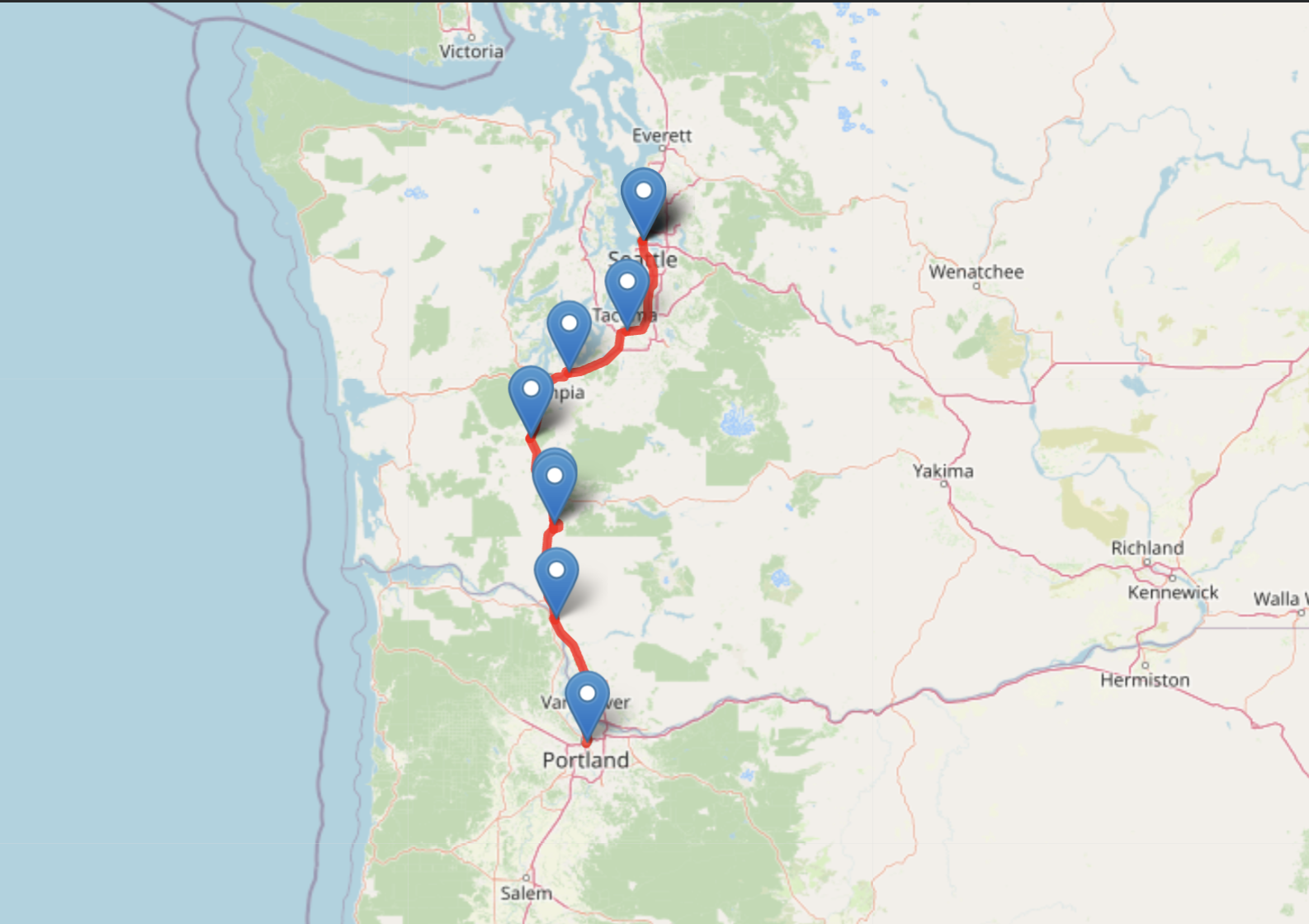
The system generates interactive map visualizations showing the recommended route with Points-of-Interest marked along the path. The example above demonstrates a road trip recommendation from Portland to Seattle, highlighting how TRAR balances route attractiveness with destination quality to create an optimized itinerary.